
Database
Manage databases with storage-computing separation architecture, enabling flexible connections and independent operations.
Databases in Tacnode use a storage-computing separation architecture, allowing flexible connections between data storage and computing resources (Nodegroups). This design enables databases to operate independently or connect to specific Nodegroups as needed.
Database Architecture
Storage-Computing Separation Benefits:
- Databases can exist without computing resources
- Flexible attachment and detachment from Nodegroups
- Independent scaling of storage and computing
- Cost optimization through selective resource allocation
Database-Nodegroup Relationships
Connecting Databases to Nodegroups
Method 1: SQL Creation
CREATE DATABASE database_name;Creates a new database within the current Nodegroup, automatically visible on the Context Lake “Database” page.
Method 2: Attach Existing Database Attach an independent database to a specific Nodegroup for SQL operations.
Method 3: Backup and Restore Restore database backups to target Nodegroups for data recovery or migration.
Disconnecting Databases from Nodegroups
Method 1: SQL Deletion
DROP DATABASE database_name;Permanently removes the database and all its data.
Method 2: Detach Operation Detaches the database from the Nodegroup while preserving all data for future reattachment.
Status Updates: Changes in database-Nodegroup relationships and storage size updates may take several minutes to reflect in the interface.
Database Overview and Search
The database management page displays comprehensive information about all databases in your Context Lake:
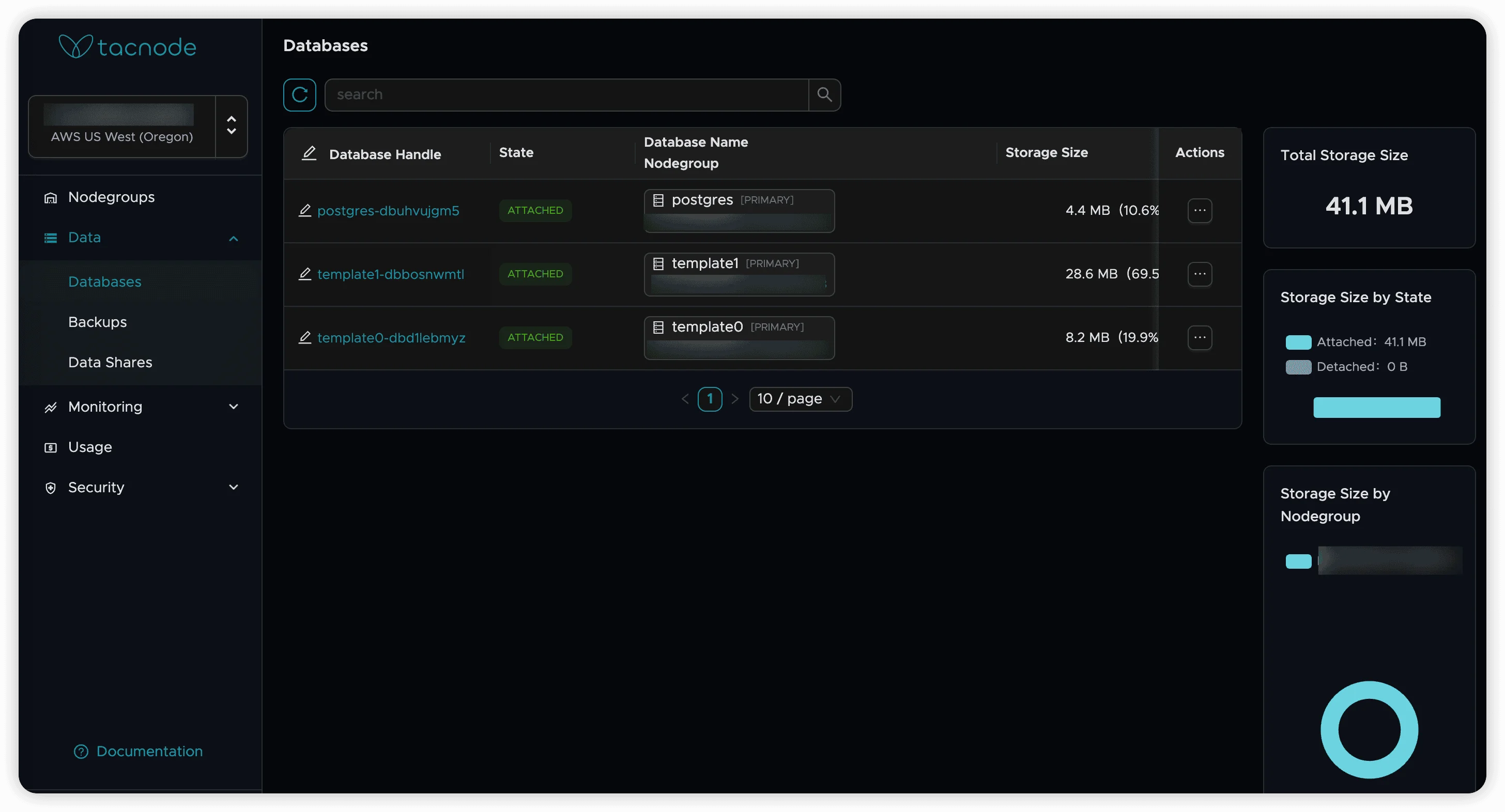
Key Information Displayed
- Handle: Unique database identifier
- Database Name: Combined database and Nodegroup identifier
- Status: Attached or Detached from Nodegroups
- Storage Size: Current data storage utilization
- Summary Statistics: Total storage, status breakdowns, per-Nodegroup allocation
Advanced Search Capabilities
Fuzzy Search Enter keywords to search across multiple fields:
postSearches Handle, NodegroupName, DatabaseName, and other relevant fields.
Exact Field Matching
Use field:value syntax for precise searches:
| Search Type | Example | Description |
|---|---|---|
| Handle | handle:postgres-9c1475d0 | Exact handle match |
| Database Name | DatabaseName:postgres | Exact database name |
| Nodegroup ID | NodegroupId:wb3vlgqzev | Specific Nodegroup identifier |
| Nodegroup Name | NodegroupName:v_nodegroup | Nodegroup name match |
| Status | state:attached | Filter by attachment status |
Search Combinations
- Combine fuzzy and exact searches:
post NodegroupName:production - Multiple exact matches:
state:attached DatabaseName:analytics - Case Sensitivity: Field names are case-insensitive, values are case-sensitive
Search Behavior: For multiple keywords, only the last keyword results are displayed. For duplicate field matches, only the final field’s results are shown.
Database Operations
The platform provides comprehensive database management capabilities:
Core Operations
Rename (Handle Update)
- Modify the database handle (identifier) for better organization
- Must remain unique within the Context Lake
- Available for single databases or bulk operations
- System-generated handles use database name as prefix
Attach/Detach Management
- Detach: Remove database from Nodegroup (requires “Running” status)
- Attach: Connect database to specific Nodegroup (requires “Running” status)
- Data is preserved during detachment for future reattachment
Backup and Restore
- Backup: Create database snapshots (requires “Running” status)
- Restore: Recover data to target Nodegroup (requires “Running” status)
- See Backup and Restore documentation for details
Delete Operation
- Permanently removes database data (equivalent to
DROP DATABASE) - Requires Nodegroup in “Running” status
- Irreversible action - ensure data backup if needed
Database Details and Monitoring
Access comprehensive database information through the details page:
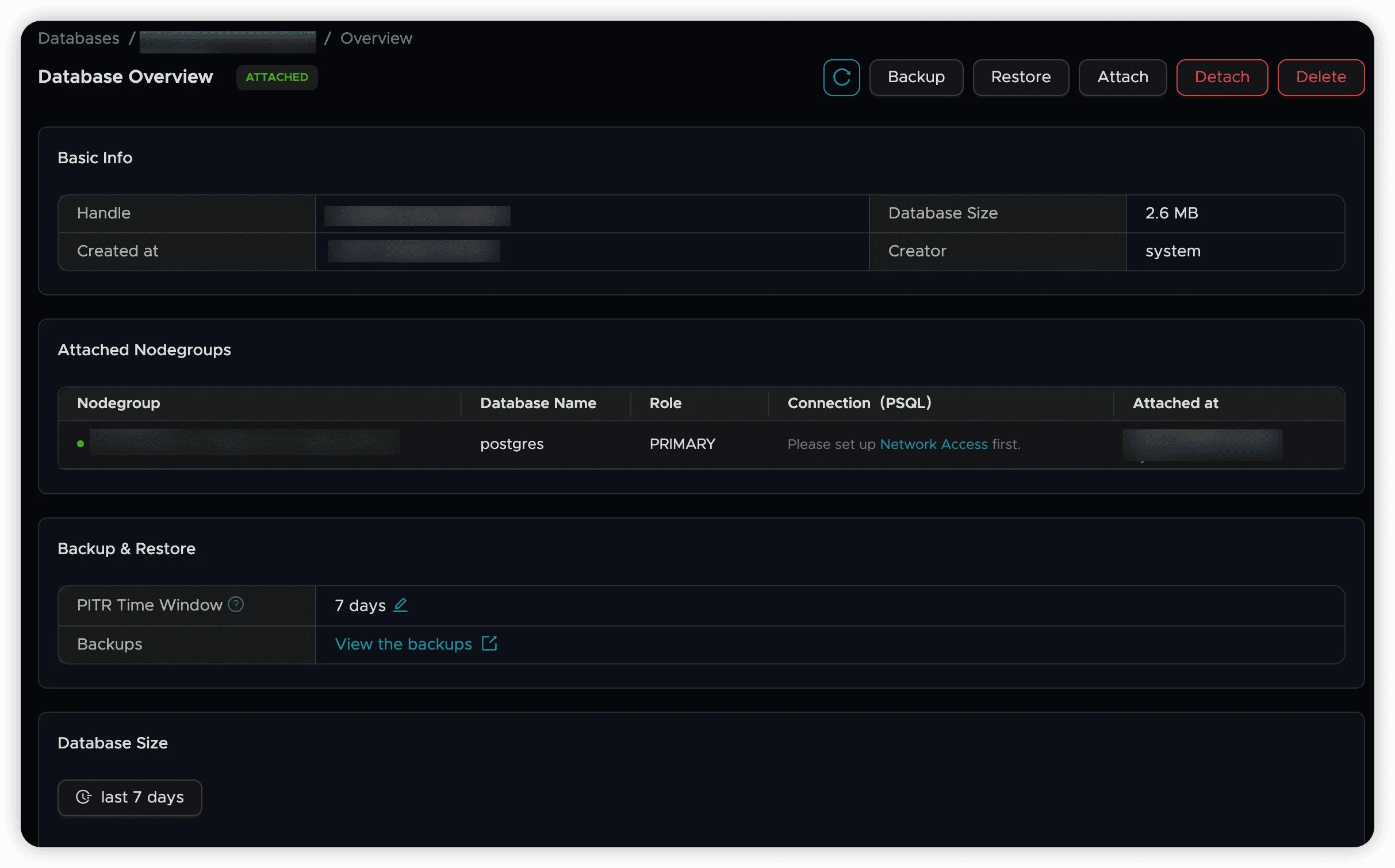
Available Features:
- PITR Configuration: Set Point-in-Time Recovery windows
- Storage Analytics: Monitor storage usage over time
- Custom Time Ranges: Analyze historical storage patterns
- Performance Metrics: Track database utilization trends
Storage Monitoring
- Visual storage size curves over customizable time periods
- Historical data analysis for capacity planning
- Usage pattern identification for optimization
Operation Requirements: Most database operations require the associated Nodegroup to be in “Running” status.