Primary Key Design: Best Practices for Performance and Scale
Your analytical queries are slow—and it's probably not indexing. I've seen query latency double without any code changes, just from a bad primary key choice. Here are the 3 patterns that actually work at scale.
TL;DR: Primary key design determines how data is physically organized, not just how rows are identified. Three patterns that work at scale: design keys around query access patterns (not abstract identity), use composite keys that match your most common WHERE clauses, and put the most selective filter column first in composite key order. Random UUIDs destroy data locality. Poorly designed keys force full scans where incremental updates should suffice. In continuously updating systems, primary key design is the difference between stable and degrading query performance.
Primary key design is one of the most important—and most frequently underestimated—factors in database query performance.
On paper, a primary key exists to uniquely identify a row. In production systems, primary key design determines how data is physically organized, how efficiently queries execute, and how well performance holds up as data volume grows, updates arrive continuously, and concurrency increases. In many SQL databases, the primary key is implemented as a clustered index, which means the physical order of the table's data is determined by the primary key. This directly impacts index usage and query performance, especially for SELECT and JOIN operations.
I've seen systems where query latency doubled without any change in query logic, simply because the primary key was chosen without considering real access patterns. That kind of mistake becomes even more expensive in modern architectures that support real-time analytics, feature generation, and AI-driven applications, where freshness and predictable performance are non-negotiable.
When working with SQL databases, the sql primary key is the mechanism that uniquely identifies each row, ensuring data integrity and supporting normalization and indexing. This article explains how primary key design affects query performance, the tradeoffs that actually matter, and how to approach primary keys in systems that are continuously updating.
What primary key design controls in practice
Primary key choice affects…
What changes in practice
Row lookup speed
Whether queries hit narrow key ranges or scan large sections of the table
Data locality
Whether related rows are physically stored together or scattered
Join efficiency
How much data must be read and matched during joins
Update propagation
Whether updates stay local or fan out across indexes and views
Concurrency behavior
Lock contention, cache churn, and stability under concurrent reads and writes
Data integrity and entity integrity
Data integrity is a foundational element of any relational database, and the primary key plays a central role in enforcing it. By definition, a primary key constraint ensures that every record in a table is uniquely identifiable—no two rows can share the same primary key value, and null values are strictly prohibited in primary key columns. This prevents duplicate records and guarantees that each entity in the table can be referenced with confidence.
Entity integrity, a core principle of the relational model, is directly enforced by the primary key. The primary key constraint requires that each row has a unique, non-null key, making it impossible for the database to accept duplicate values or missing identifiers. This not only maintains the accuracy and consistency of the data, but also supports reliable data entry and retrieval across the system.
In practice, maintaining data integrity through primary keys means that every record is both uniquely identifiable and protected against accidental duplication or omission. This is especially critical in environments where data is ingested and updated in real time, as even a single violation of entity integrity can cascade into larger inconsistencies throughout the database. By enforcing these constraints, primary keys uphold the trustworthiness and reliability of the entire data infrastructure.
Establishing relationships through primary keys
Primary keys are not just about uniquely identifying records—they are also the backbone of relationships between tables in relational databases. When a primary key in one table is referenced by a foreign key in another, it creates a direct link between related tables, enabling efficient data retrieval and robust data modeling.
For example, consider a customer table where each customer has a unique customer ID as the primary key. In an orders table, this customer ID can be used as a foreign key, connecting each order to the corresponding customer. This relationship allows queries to efficiently retrieve all orders for a specific customer, or to join customer and order data for analytics and reporting.
Establishing relationships through primary keys and foreign keys not only supports complex queries across related tables, but also enforces referential integrity. The database engine ensures that every foreign key value matches an existing primary key value in the referenced table, preventing orphaned records and maintaining consistency across the system. This structure is essential for managing multi-table data models, supporting scalable applications, and ensuring that data remains accurate and connected as it grows.
By leveraging primary keys to establish and enforce relationships, relational databases can efficiently manage and query interconnected data, supporting everything from simple lookups to advanced analytics and AI-driven workloads.
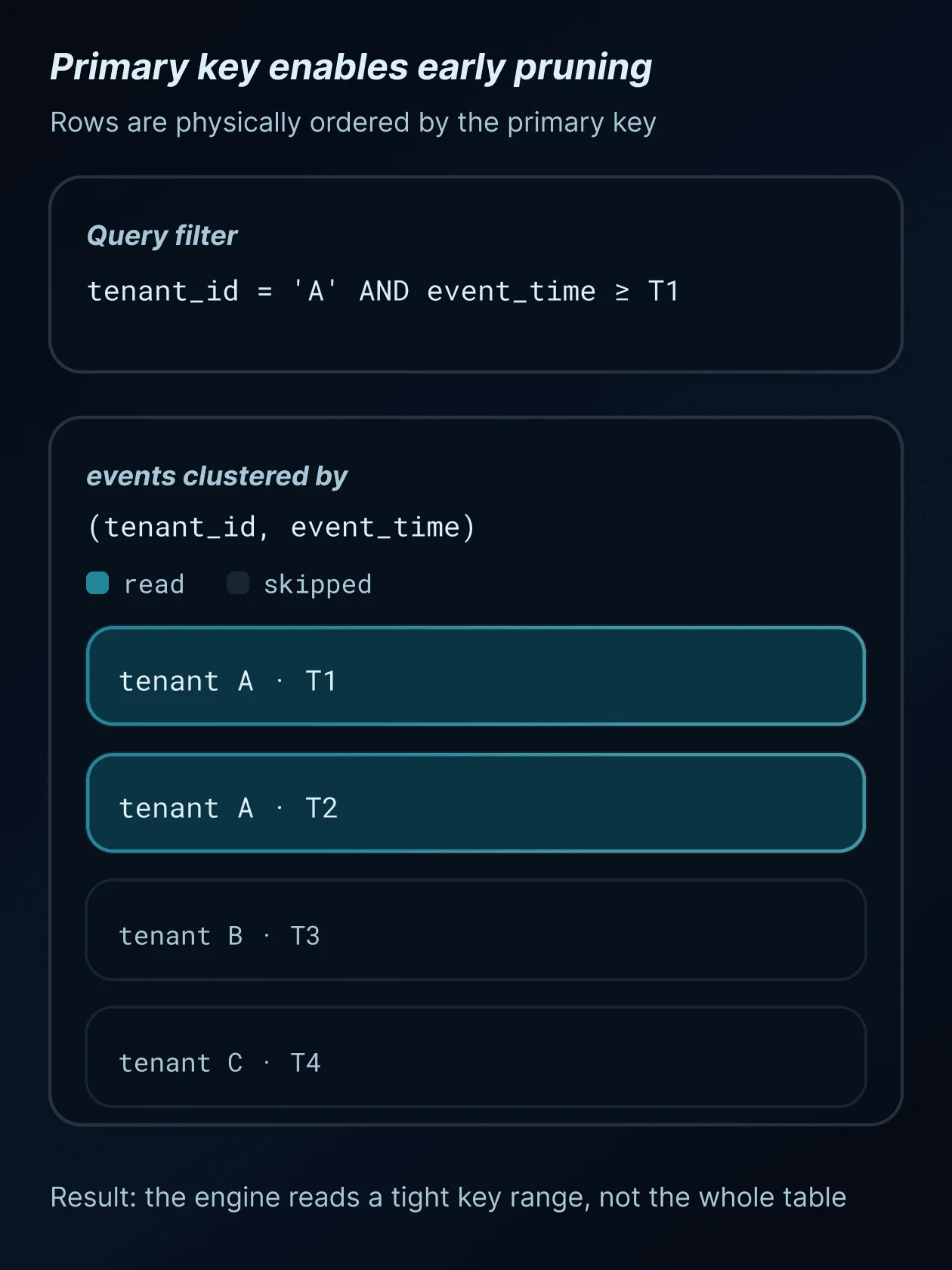
Designing primary keys around query access patterns
The most common mistake in primary key design is optimizing for identity instead of access.
A globally unique surrogate identifier may satisfy correctness requirements, but if most queries filter by tenant, account, user, or time range, that primary key provides little benefit for query performance. The database still has to scan large portions of the table to answer routine queries.
Effective primary key design starts by understanding how data is accessed in practice. That includes: which columns appear most often in the WHERE clause for filtering results, how queries are scoped (by tenant, entity, or account), whether time-based filtering is common, and how frequently rows are updated.
A primary key should be defined as the minimal set of one or multiple columns that uniquely identify each record and align with query access patterns.
A primary key that aligns with these access patterns allows the database to prune data early, reduce unnecessary scans, and maintain stable query performance as the system scales.
Single-column and composite primary keys
Single-column primary keys are simple and widely used. They work well for lookup-heavy workloads and straightforward joins, especially when access patterns are uniform.
Composite primary keys, also known as composite keys, often provide better query performance in analytical and real-time systems. A composite key is a primary key composed of various columns, combining two or more columns to uniquely identify each record—such as a tenant identifier and a timestamp or an entity identifier and an attribute name.
When designed correctly, composite primary keys improve query performance by: preserving data locality, reducing the amount of data scanned, making filters more selective (since using various columns as part of a composite key can improve selectivity and query performance), and supporting efficient incremental updates.
The tradeoff is complexity. Composite primary key design requires more upfront thought, but in systems where query performance and freshness matter, that complexity usually pays for itself.
Column order in composite primary keys
In composite primary key design, column order is critical.
Most databases optimize for left-most prefixes of a primary key. A primary key defined as (tenant_id, event_time) efficiently supports queries filtered by tenant_id, but does not help queries filtered only by event_time.
Incorrect column ordering is a frequent source of unexpected query performance issues. Primary key design should reflect the most common and most selective filters used in queries, not abstract modeling ideals.
Business keys versus surrogate keys
Another recurring decision in primary key design is whether to use business keys or surrogate keys.
Business keys encode real-world meaning, such as email addresses or external identifiers. Common examples of natural keys include account number and social security number. Surrogate keys are artificial identifiers like integers or UUIDs. Surrogate keys are also known as artificial keys and are often implemented as an identity column or auto generated value.
A surrogate primary key is used when a natural key is unstable or too large for efficient indexing. In such cases, alternate keys and unique keys can be defined with a unique constraint to enforce uniqueness on business attributes, ensuring data integrity even when the surrogate key is used as the primary identifier.
From a query performance perspective: surrogate keys are compact and efficient for joins, business keys are often wider and more expensive to index, and surrogate keys alone often fail to align storage with access patterns.
In many production systems, a hybrid approach works best. Surrogate keys are used for identity, while primary keys or secondary indexes are designed to support common query patterns. The choice between a natural key and a surrogate key should be made on a case by case basis, considering data stability and future requirements. The goal is not theoretical purity, but predictable performance.
UUIDs, integers, and write performance
The choice between UUIDs and integers has meaningful performance implications.
Random UUIDs disrupt data locality, increase index fragmentation, and place additional pressure on caches. Sequential integers preserve locality and generally improve query performance, but can introduce coordination challenges in distributed systems.
Modern systems often use time-ordered UUIDs or composite primary keys that include temporal components to balance uniqueness, distribution, and query performance. The right choice depends on ingestion patterns, update frequency, and query behavior.
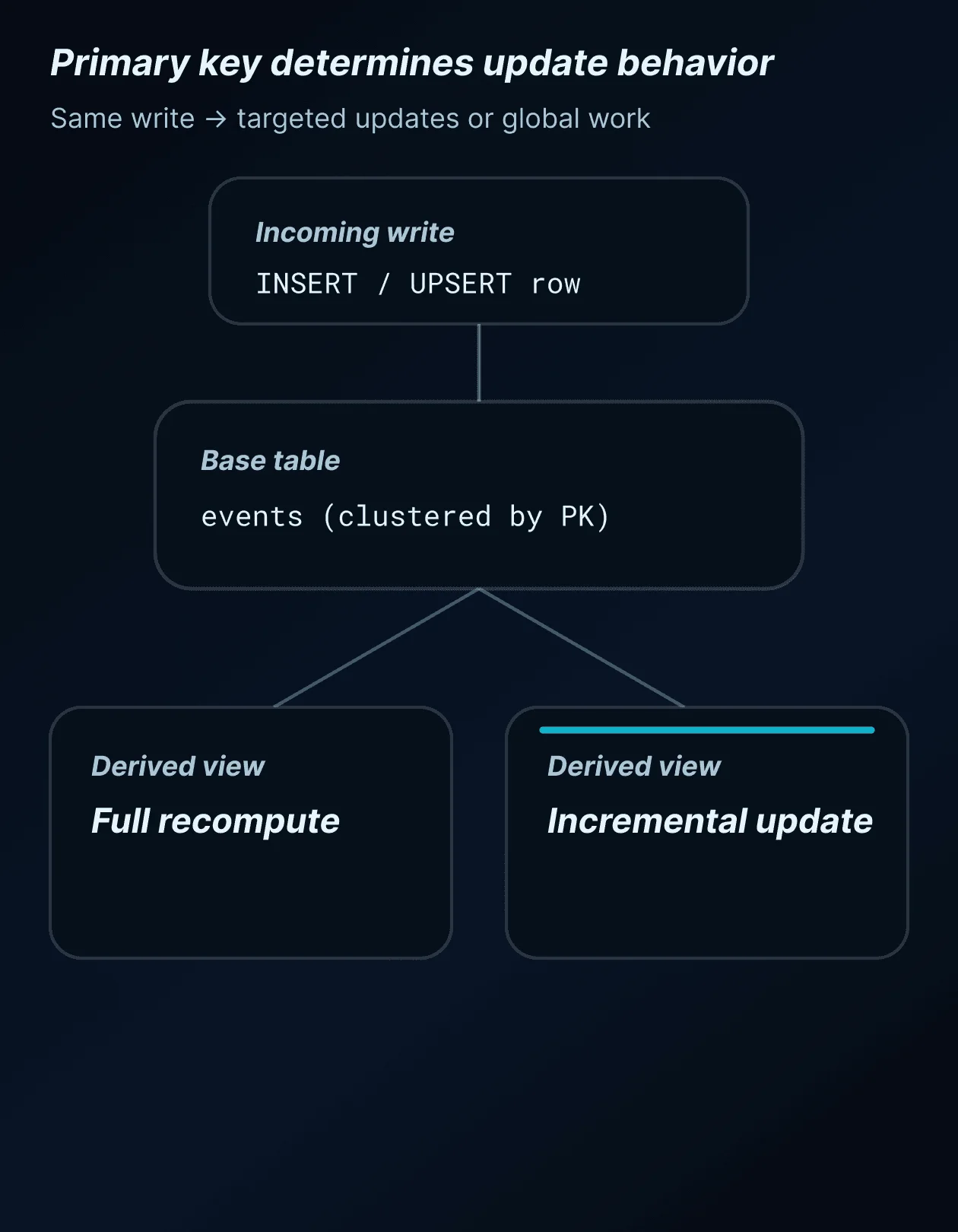
Primary key design in continuously updating systems
Traditional primary key advice often assumes batch ingestion and periodic recomputation. That assumption breaks down in systems that ingest data continuously and serve low-latency queries.
In real-time and AI-centric architectures, primary key design affects: how quickly updates become visible to queries, whether incremental computation is possible, how derived tables and materialized views stay fresh, and how expensive recomputation becomes under load.
A poorly designed primary key can force full scans or full recomputes where incremental updates should be sufficient. A well-designed primary key allows systems to update only what changed and keep query performance stable as freshness requirements increase.
Common primary key design mistakes
Several patterns reliably lead to query performance problems:
Choosing a primary key without considering query filters. Using wide, high-cardinality keys unnecessarily. Ignoring update frequency when designing keys. Treating primary keys as immutable even as workloads evolve. Optimizing for theoretical correctness instead of real queries.
These issues rarely appear immediately. They tend to surface as data volume grows or when systems are extended to support real-time analytics or AI workloads.
Evaluating your current primary key design
If you are unsure whether your primary key design supports query performance, ask: Do common queries align with the primary key ordering? Can filters prune data early in execution? Do updates cause excessive index churn? Do derived views require full recomputation? Does latency degrade as concurrency increases?
If several of these are true, the primary key is likely contributing to performance issues.
If your evaluation reveals that the primary key design is insufficient, you may need to modify the existing table using an ALTER TABLE statement to add or change the primary key. In SQL and PostgreSQL, defining a primary key on an existing table automatically creates a unique index, which enforces uniqueness, maintains data integrity, and improves query performance. This is especially important when establishing relationships using foreign keys or when choosing between surrogate and natural keys.
Closing thoughts
Primary key design is not glamorous, but it is foundational. It shapes how data is stored, updated, and queried long after the schema is defined.
In modern systems where freshness, concurrency, and incremental computation matter, primary keys deserve more attention than they usually get. The best primary key designs are pragmatic, workload-aware, and biased toward the queries that actually matter. When primary key design is done well, many query performance problems never appear in the first place.