
Positioning
Learn how Tacnode Context Lake enables coherent AI decisions through Shared, Live, and Semantic context.
The Real Problem
Modern systems don’t struggle because data is split across databases. They struggle because decisions are made with incomplete, inconsistent, or outdated context.
Services, agents, and applications act continuously while state is still changing. Traditional data systems were designed for settled state — write first, read later — not for decisions made mid-flight.
Transactional state lives in OLTP databases. Features and aggregates are computed elsewhere. Search and retrieval run in separate engines. Over time, data spreads across systems as a workaround. When no system owns decision-time data, teams reconstruct meaning in application code, pipelines, and glue logic. Because this happens independently, concurrent decisions evaluate the same reality differently.
Shared · Live · Semantic
Tacnode Context Lake enforces three properties so decisions evaluate against the same reality:
Shared — One Shared Reality
All decision-makers retrieve context — raw and derived — from the same shared reality. No silos.
- Multiple agents and services query the same state
- No conflicting snapshots under concurrency
- What one agent writes is immediately visible to all
Live — No Stale Context
Decisions evaluate against current context — not delayed updates or eventual reconciliation.
- Data becomes queryable the instant it arrives
- Features and aggregates update incrementally as data changes
- No batch lag, no stale caches, no “pipeline catching up”
Semantic — Meaning as a First-Class Primitive
Context carries shared interpretations, so decisions don’t diverge over what the data means.
- Embeddings, classifications, and derived features computed within the transactional boundary
- All consumers share the same semantic state
- Predicates and interpretations are evaluated atomically with state
Tacnode Context Lake Architecture
Tacnode Context Lake is a single integrated system — not a composition of loosely coupled services. It’s PostgreSQL-compatible and optimized for multi-cloud environments.
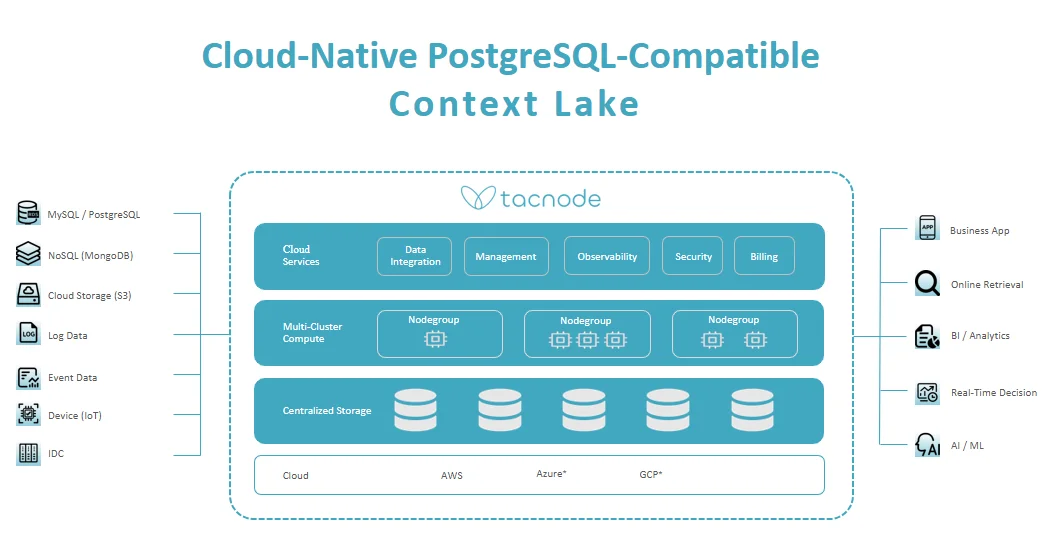
System Design Principles
Single Integrated System Tacnode is built as one cohesive system rather than a composition of loosely coupled services. No external reconciliation. No cross-system coordination. Guarantees hold end-to-end.
Separation of Compute and Storage Compute scales independently from storage so decision workloads can expand and shrink without moving data. This enables workload isolation: independent agents and services run concurrently without interfering with each other’s latency or throughput.
Temporal Versioning by Construction All state is versioned over time as part of the core system, not reconstructed from logs or replay pipelines. Time-aware decisions. Correct “as-of” evaluation. Safe replay and simulation.
PostgreSQL-Compatible by Construction Tacnode is designed to speak PostgreSQL natively, so compatibility is a first-order constraint — not a translation layer.
Data Ingestion Layer
Supports a wide range of data source types to meet evolving enterprise data needs:
- Relational databases: MySQL, PostgreSQL, and others
- NoSQL databases: MongoDB and others for flexible storage and querying of semi-structured data
- Cloud object storage: Amazon S3 for managing large-scale data storage and retrieval
- Streaming data: Kafka, CDC, and event streams
- IoT device data: for gathering data from various IoT devices
Data Storage Layer
Built on cloud storage resources, Tacnode’s centralized storage abstraction layer efficiently manages and schedules data storage in a multi-cloud environment:
- Columnar + hybrid storage for both analytical scans and point lookups
- Tiered storage: hot data in high-performance storage, cold data moves automatically to cost-effective object storage
- Data backup and replication across cloud providers (AWS, Google Cloud, Azure)
Distributed Computing Layer
Features Nodegroups — Tacnode’s main computational resource:
- Each Nodegroup consists of computing units that can be elastically scaled according to demand
- Workload isolation ensures different workloads don’t interfere with each other
- Containerization technology and cloud-native scheduling optimize resource allocation
Cloud Services Layer
- Data Integration: Simplifies data inflow with built-in sync from external sources
- Observability: Monitor system status, optimize performance, respond to events
- Security: Data encryption, access control, audit logging, compliance
- Billing: Transparent and flexible billing for services used
API and Service Layer
The top layer provides application integration and service interfaces:
- PostgreSQL wire protocol for all database operations
- Search service for full-text and semantic search
- Real-time decision platform for stream processing and automated workflows
- AI/ML integration for feature serving, RAG, and agent memory