
What is Tacnode
Tacnode Context Lake for coherent AI decisions.
Tacnode is a Context Lake — a unified data system designed so AI agents and services make coherent decisions under concurrency. Instead of scattering data across transactional databases, data warehouses, search engines, vector stores, and stream processors, Tacnode maintains a shared, live, and semantic context in a single system.
Modern systems don’t struggle because data is fragmented. They struggle because decisions are made with incomplete, inconsistent, or outdated context. Services, agents, and applications act continuously while state is still changing. Traditional data systems were designed for settled state — write first, read later — not for decisions made mid-flight.
Tacnode owns decision-time context. It ingests state and signals as they arrive, maintains shared interpretations and derived facts, and serves that context with strict guarantees under concurrency. Decisions evaluate against the same live reality — not reconstructed fragments of it.
Decision Coherence
Decision Coherence is the guarantee that concurrent decisions evaluate against the same shared reality. Tacnode enforces three properties that make this possible:
Shared
All decision-makers retrieve context — raw and derived — from the same shared reality. No silos. When multiple agents or services query the Context Lake, they see the same state, eliminating conflicts that arise from fragmented data.
Live
Decisions evaluate against current context — not delayed updates or eventual reconciliation. Data becomes queryable the instant it arrives. There’s no batch lag, no stale caches, no “pipeline catching up.”
Semantic
Context carries shared interpretations, so decisions don’t diverge over what the data means. Embeddings, classifications, and derived features are computed within the same transactional boundary, ensuring all consumers share the same semantic state.
Why Tacnode
Real-Time by Default Most data systems were designed when “yesterday’s numbers” were good enough. Tacnode is designed for a world where milliseconds matter — whether it’s detecting fraud as it happens, powering an AI agent that can’t afford to hallucinate outdated answers, or making personalization decisions before the page renders.
- Data is queryable the instant it arrives
- No pipelines that need to “catch up” before you see results
- Applications, analytics, and AI agents all react in real time
Unified Architecture Instead of stitching together five or six different engines, Tacnode runs them all natively inside the Context Lake:
- No ETL pipelines between systems — everything lives in one place
- No schema gymnastics to convert between formats — structured rows, JSON, documents, embeddings, and time-series events all work out of the box
- No syncing headaches — you’re not constantly worrying about data drifting between systems
AI-Native AI doesn’t just need raw data — it needs context. Tacnode bakes this in at the storage and query layer:
- Vectors and embeddings are first-class citizens — not bolt-ons
- Run hybrid queries: structured + text + vector similarity, all in one SQL statement
- Retrieval-augmented generation (RAG) and intelligent agents are natural use cases, not hacks
Developer-Friendly Tacnode is PostgreSQL-compatible, making it accessible to teams that don’t have the time (or appetite) to learn a whole new stack:
- Your existing SQL knowledge works — no need to learn a new query language
- Keep using PostgreSQL drivers, ORMs, and BI tools you already know
- Migration paths are straightforward — swap in Tacnode without rewriting your app
Cloud-Native Tacnode is built for the cloud era, not for racks of servers in a datacenter:
- Elastic scaling — spin up or down with workload demand
- Pay for what you use — no idle clusters burning money
- Multi-cloud support — deploy where your business needs it
Product Architecture
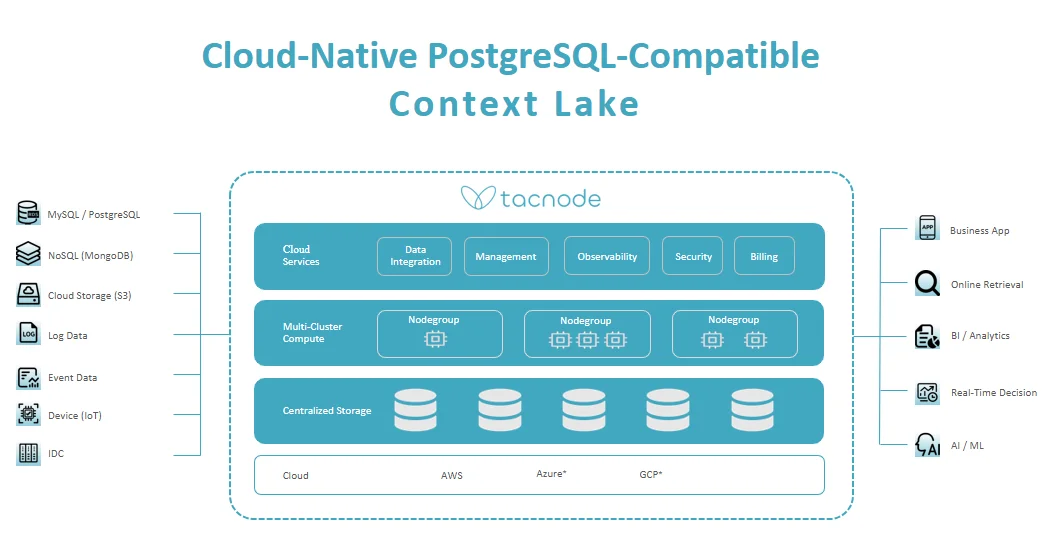
Tacnode is built from the ground up as a single integrated system rather than a composition of loosely coupled services. Here’s how the layers fit together:
Context Ingestion
- Accepts multiple formats — SQL inserts, JSON events, documents, logs, embeddings
- Ingests at high throughput with millisecond-level latency
- Automatically indexes for queries across transactional, analytical, and vector workloads
Unified Storage Engine
- Handles both row-oriented (transactional) and columnar (analytical) access patterns
- Optimized to keep hot data in memory while scaling to terabytes or petabytes
- No need to choose between a transactional DB or an OLAP warehouse — you get both
Query Layer
- Fully SQL-compatible with PostgreSQL syntax support
- Capable of joining live event streams with historical data in one query
- Supports joins across structured, semi-structured, and vector data sources
AI/Vector Layer
- Embeddings can be ingested directly or generated on the fly
- Built-in similarity search, nearest neighbor lookups, and hybrid ranking
- Perfect for semantic search, RAG, recommendations, and personalization
Streaming Core
- Real-time event processing with incremental materialized views
- Built-in triggers for alerting, risk checks, and automated workflows
- Eliminates the need for a separate event bus or stream processor
Core Concepts
Context Lake
The unified boundary where all context — structured, semi-structured, and vector data — lives within a single transactional system. Instead of scattering information across systems, Tacnode keeps everything unified so decisions evaluate against complete, current state.
Nodegroup
A Nodegroup is the computing module used for executing SQL commands. Each Nodegroup operates with its own resources and can dynamically scale up or down as needed. They are completely independent from one another, ensuring workload isolation. You have the flexibility to create multiple Nodegroups based on your business needs.
Incremental Materialized Views
Define transformations declaratively in SQL. They execute continuously as data arrives — no external orchestration, no batch scheduling. Features, aggregations, and derived context stay consistent with live state.
Real-Time Indexing
Data becomes queryable the instant it’s ingested. No batch jobs, no nightly ETL, no “pipeline lag.”
Temporal Versioning
All state is versioned over time as part of the core system, not reconstructed from logs or replay pipelines. This enables time-aware decisions, correct “as-of” evaluation, and safe replay and simulation.
Workload Isolation
Multiple workloads can operate in parallel against shared context without interfering with each other. Analytical queries don’t block transactions, ingestion doesn’t slow retrievals.