What is Semantic SQL?
Understanding an emerging approach to querying complex, AI-driven context


Understanding an emerging approach to querying complex, AI-driven context
As teams build AI applications that pull from relational tables, streaming events, embeddings, and derived features, they’re running into a familiar problem: the data needed for accurate reasoning is scattered across systems. Traditional SQL works well when everything you need lives in the warehouse. It breaks down when context is fragmented across pipelines, caches, feature stores, vector DBs, and search layers.
“Semantic SQL” has emerged as a response to this complexity. The idea is simple: make queries reflect meaning, not storage layout. Give developers one way to ask questions across structured data, events, and embeddings without stitching it together by hand. This aligns with the direction we describe in the Tacnode Product Overview, where unifying context is a foundational architectural choice rather than an abstraction added later.
Semantic SQL aims to let developers express intent—“find similar customers who recently churned,” “locate events that indicate anomalous device behavior,” “retrieve products relevant to this query and inventory state”—without needing to know the physical shape of the data underneath.
This typically requires:
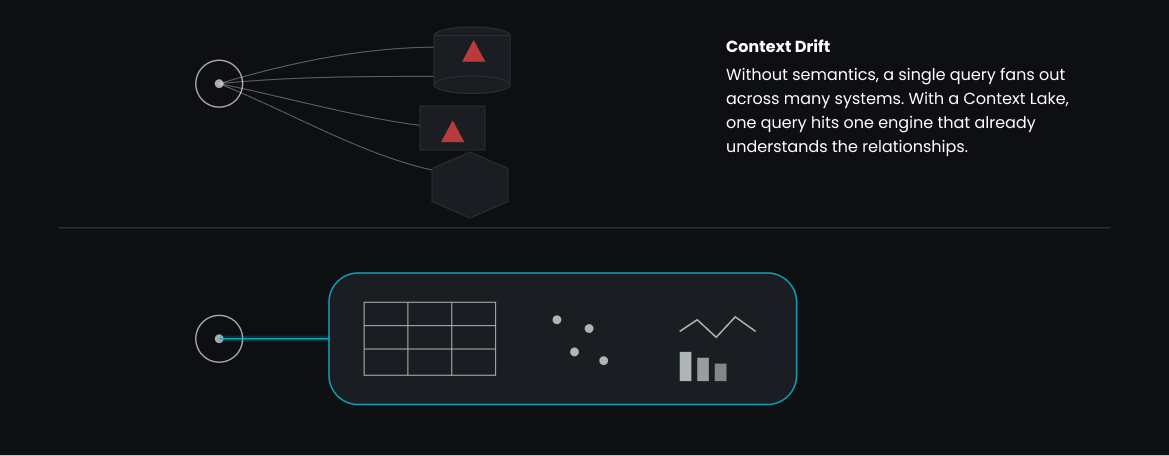
It’s SQL extended with a richer understanding of how the underlying data connects. Many of these principles are built directly into a Context Lake, explained further in What Is a Context Lake?.
The concept isn’t new. The difficulty is making it work in real systems. Most architectures distribute context across specialized engines: one for transactions, one for analytics, one for vector embeddings, one for streams. Even if developers want a unified semantic layer, the data isn’t unified underneath it.
As soon as you rely on pipelines or sync jobs to bring everything together, the semantics drift. You end up with the same inconsistencies that already challenge real-time AI:
Embeddings that don’t match live state
We cover similar fragmentation issues in Why Tacnode, where multi-system architectures fail to support real-time AI workloads.
For Tacnode, Semantic SQL isn’t a UI polish or an abstraction layer. It’s a property of the data engine itself. You can’t fake semantics if the system storing the data can’t maintain coherence across relational, vector, and streaming context.
In Tacnode, SQL queries—semantic or otherwise—operate on a single, unified substrate that incorporates the same architectural principles outlined on our Product Architecture page:
When everything lives in one model, semantics are not something you bolt on. They emerge naturally from the way data is ingested, updated, and retrieved.
In a Context Lake, the semantics derive from the fact that context is consistent at any moment in time. A query that joins embeddings, transactional history, and live event streams works because the engine guarantees alignment across these signals.
Examples include:
Developers don’t need to reason about pipelines or syncs. They write SQL that reflects how the data should relate, and the engine makes it true. This is the same principle powering our Solutions for AI Agents, where consistent real-time context makes agentic loops reliable instead of brittle.
AI systems increasingly rely on hybrid context—structured attributes, behavioral signals, semantic similarity, and temporal patterns. Without a unified way to query them, teams end up building custom orchestration code around every step.
Semantic SQL provides a simpler approach: describe the question, let the engine retrieve the right blend of context.
This matters for:
Tacnode aligns with the direction Semantic SQL is pointing toward—but on more foundational terms. Our view is that semantics only matter if the system ensures:
Once those properties are guaranteed, extending SQL with semantic constructs isn’t just possible—it becomes the natural way to work. Tacnode’s Context Lake makes Semantic SQL practical because semantics aren’t inferred; they’re preserved.
Semantic SQL reflects a real need. Developers want a simpler way to query complex, fast-changing context without stitching together multiple systems. The idea has momentum because it addresses pain felt across AI and analytics teams.
Where most approaches add a layer, Tacnode builds the semantics into the engine. That’s the difference between a promising concept and a reliable foundation for real-time AI.
As AI applications grow more dependent on unified, instant context, Semantic SQL will become the default way teams interact with their data. It will only work for systems built to sustain it—systems like Tacnode’s Context Lake.
If you want to explore how Semantic SQL behaves in practice on Tacnode, start with the Tacnode Docs or request a session through the Get a Demo page.