What Is a Feature Store? Feast, Tecton & AWS Compared
A feature store is the infrastructure layer that manages, stores, and serves ML features for both training and real-time inference. It prevents training-serving skew by ensuring your model sees the exact same features in production that it trained on. Here's the architecture and what to evaluate.
TL;DR: An online feature store is a specialized low-latency database that serves ML features at inference time — with feature semantics, freshness guarantees, and lineage tied to a central registry. Architecture includes offline store (training), online store (serving), feature pipelines, feature registry, and serving APIs. Key challenge: preventing training-serving skew by ensuring training and inference use the same feature definitions. As AI workloads grow more complex, unified Context Lakes are emerging to collapse offline/online stores into a single system with continuous freshness and multi-entity join support.
Real-time machine learning emerged to overcome the limitations of traditional data architectures, which often struggle to provide the low-latency, high-throughput feature retrieval necessary for production ML inference. Online feature stores were introduced to bridge this gap, offering specialized infrastructure that serves feature data quickly and consistently during model inference.
A centralized feature store is a key component in modern machine learning infrastructure, streamlining feature management and improving model performance through standardization and reusability.
What is an Online Feature Store?
An online feature store is a specialized, low-latency database designed to serve feature data at inference time. Unlike generic key-value stores, online feature stores understand feature semantics, enforce freshness guarantees, and maintain lineage to your machine learning pipelines. When your production model makes a prediction, the online store delivers the latest feature values for a given entity—such as a user, transaction, or device—in milliseconds. Selecting appropriate features for real-time applications is critical to ensure low-latency serving and optimal model performance.
In practice, an online feature store is the serving layer of a broader feature platform. While teams often attribute capabilities like lineage tracking, feature validation, and governance to the online store, those concerns are typically handled by adjacent systems such as the feature registry, offline store, and pipeline orchestration layer. The online store's primary responsibility is fast, reliable feature retrieval at inference time. Feature stores act as centralized systems that manage, store, and serve features for both training and real-time inference, supporting collaboration and data consistency across the ML lifecycle.
What sets an online feature store apart from a simple cache are three key aspects: feature definitions tied to a central registry, consistency between training and serving environments, and built-in feature monitoring and governance. Feature stores serve as the backbone for providing real-time and historical feature data to ML models. This means you're storing curated, versioned, and validated feature data—including precomputed features, which are essential for enabling low-latency predictions—that matches exactly what your model saw during training, helping to avoid training-serving skew and ensuring reliable predictions.
Leading solutions in this space include Databricks Feature Store, Databricks Online Feature Store, Snowflake ML Online Feature Store, AWS SageMaker Feature Store, and open-source Feast with Redis or Postgres backends. Each offers unique capabilities but shares the common goal of enabling low-latency, consistent feature serving for production machine learning models.
Comparing Feast, Tecton, and AWS Feature Store
The three most-evaluated feature store solutions for online serving are Feast (open-source, BYO infrastructure), Tecton (managed, computation-included), and AWS SageMaker Feature Store (managed, AWS-native). Each takes a different approach to the core trade-off between operational simplicity and feature computation responsibility.
| Capability | Feast | Tecton | AWS SageMaker Feature Store |
|---|---|---|---|
| Deployment model | Open-source, self-hosted | Managed SaaS | Managed AWS service |
| Feature computation | External — bring your own (Spark, Flink, dbt) | Internal — declarative SQL/Python transformations | External — bring your own (Spark, Glue, EMR) |
| Online store backend | Redis, DynamoDB, Postgres, Bigtable, Snowflake | Managed (DynamoDB under the hood) | DynamoDB |
| Offline store backend | BigQuery, Snowflake, Redshift, file | Snowflake, Databricks, BigQuery, Redshift | S3 |
| Training-serving skew prevention | Best-effort (you own pipelines) | Built-in (single feature definition) | Best-effort (you own pipelines) |
| Real-time / streaming features | Supported via push API | First-class streaming features | Supported via Kinesis + custom transforms |
| Best fit | Teams that want full control + open-source | Teams that want vendor-managed feature pipelines | AWS-native ML teams already on SageMaker |
| Cost model | Infrastructure cost only | Per-feature pricing + infra | Per-store + DynamoDB read/write |
Feast is the right choice when your data team already operates Spark or Flink and wants the feature store to be the registry + serving layer, not the computation engine. It's the most flexible but pushes pipeline maintenance and training-serving consistency onto your team.
Tecton is the right choice when you want the feature store to own feature computation and eliminate training-serving skew by construction. The trade-off is vendor lock-in and per-feature pricing.
AWS SageMaker Feature Store is the right choice when your ML stack is already AWS-native and you want a managed feature store that integrates with SageMaker training and endpoints out of the box. Computation still lives in your existing AWS pipelines.
Other notable options include Databricks Feature Store (tightly coupled to the Databricks Lakehouse), Snowflake ML Online Feature Store (for teams standardized on Snowflake), and Vertex AI Feature Store (Google Cloud's managed offering). The right choice depends less on raw capability and more on where your existing data infrastructure lives.
Feature stores deliver significant advantages for organizations building and deploying machine learning models at scale. By acting as a centralized repository for feature definitions, they foster collaboration between data scientists and data engineers, making it easier to share, discover, and reuse existing features across multiple projects. This streamlines feature engineering, reducing redundant work and accelerating the development of new models.
A key benefit is the assurance that the same features used during model training are available at inference time, which helps prevent data leakage and ensures consistent model performance. Feature stores also enable robust access control, allowing organizations to manage permissions and protect sensitive feature data. With standardized feature definitions and governance built in, teams can maintain high data quality and traceability, further enhancing the reliability and trustworthiness of machine learning workflows.
Ultimately, feature stores empower organizations to scale their ML efforts efficiently, improve model accuracy, and maintain strong data governance—all while reducing operational overhead.
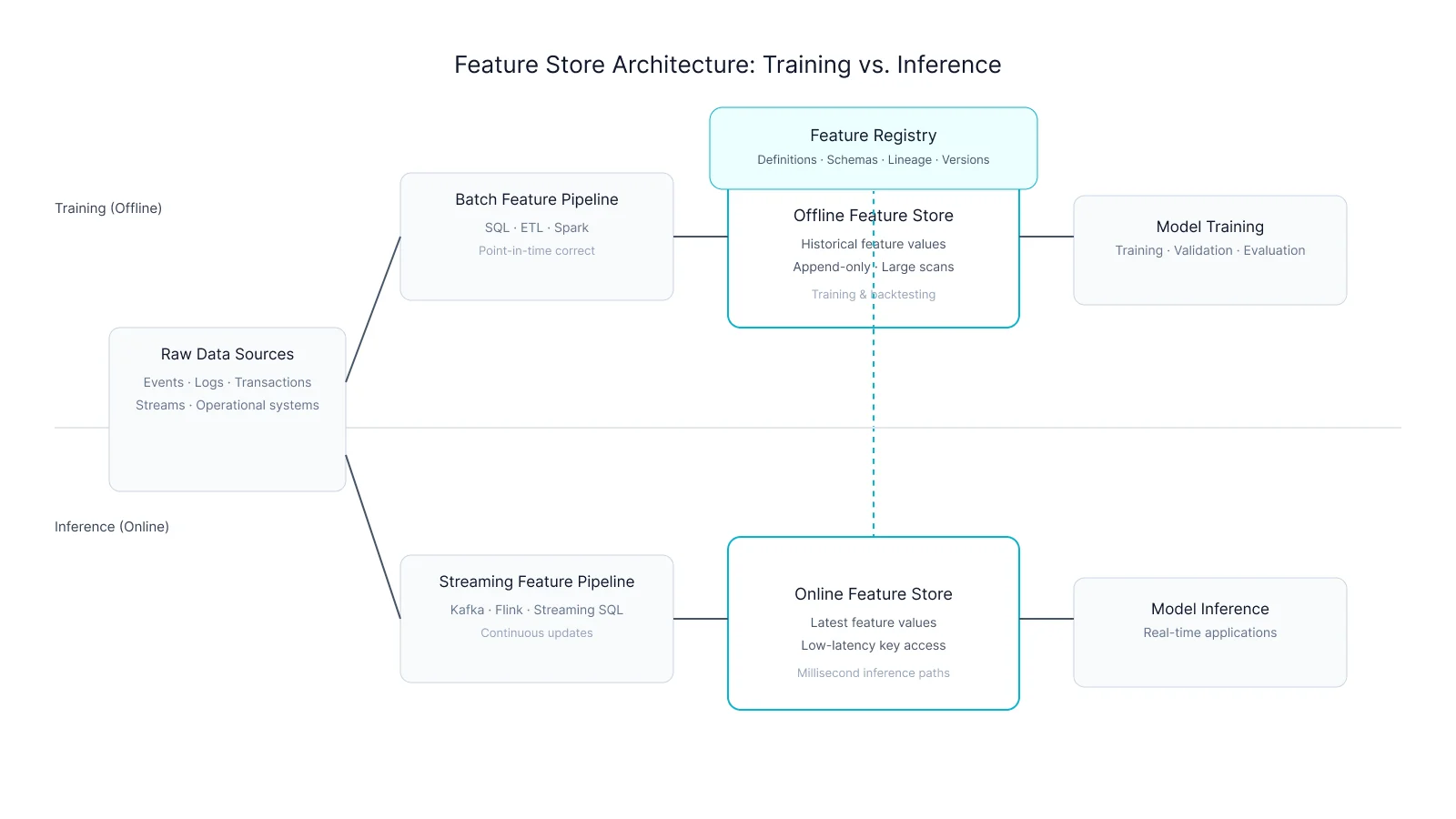
Feature Store Architecture
The easiest way to understand an online feature store is to see where it sits in the end-to-end machine learning workflow.
The diagram below shows how raw data is transformed into features, stored separately for training and inference, and served to production models — and why online feature stores exist as a distinct layer in the first place.
The architecture of a feature store typically consists of several key components. The storage layer consists of both online and offline stores, each optimized for different access patterns and latency requirements:
Offline Feature Store: This stores historical feature data in a columnar, append-only format optimized for batch processing and model training. It often leverages a data warehouse as the underlying storage layer for handling large volumes of historical feature data. It holds comprehensive historical data necessary for training machine learning models with point-in-time correctness.
Feature Pipelines: These transform raw data from multiple data sources into feature groups, applying consistent feature engineering logic. Data processing engines such as Spark or DuckDB are used to create point-in-time correct training data and implement feature logic. Both batch and streaming pipelines are used to prepare features for offline and online consumption.
Online Store: A low-latency, row-oriented database that stores only the latest feature values per entity, optimized for real-time inference. It supports very low latency access patterns required by online applications.
Feature Registry: A centralized metadata repository that manages feature definitions, data types, ownership, and lineage. It also tracks feature lineage to ensure data provenance and consistency. This registry prevents feature sprawl and ensures that features are consistently defined and used across the organization.
Serving Layer: An API or SDK that enables applications to query and retrieve online features with very low latency, supporting real-time model inference.
This architecture ensures consistency between training and serving, reduces training-serving skew, and supports scalable, real-time feature retrieval.
This architecture ensures consistency between training and serving, reduces training-serving skew, and supports scalable, real-time feature retrieval.
When transforming raw data, feature ingestion is the process of collecting, transforming, and updating raw data into the feature store, supporting both batch and streaming sources. This process also includes storing embeddings and other reusable features to facilitate reuse across multiple models and applications.
One critical nuance is point-in-time correctness. Online feature stores typically serve current feature values for inference, not historical values for training. Training datasets are reconstructed offline using time-aware transformations to ensure models only see data that would have been available at prediction time. Managing this separation — and keeping definitions aligned as features evolve — is one of the hardest operational challenges in production ML systems, making it essential to provide point in time correct feature data for temporal consistency.
Data Source
The foundation of any feature store is its ability to ingest data from a wide variety of sources, including transactional databases, data lakes, streaming platforms, and external APIs. These data sources typically provide raw, unprocessed information that must be transformed into meaningful feature values for use in machine learning.
Data scientists and engineers collaborate to design robust data pipelines that extract, transform, and load data into the feature store. These pipelines handle the complexities of data ingestion, ensuring that relevant information is captured and prepared for feature computation. Once processed, the resulting feature values are stored in both offline and online stores—supporting model training with historical data and enabling real-time inference with the latest feature values.
By integrating diverse data sources, feature stores provide a comprehensive foundation for feature computation and machine learning, ensuring that models are trained and served with high-quality, up-to-date data.
How to Build an Online Feature Store
Building an online feature store involves several important steps:
Define Feature Groups and Feature Definitions: Organize related features into logical groups with clear definitions and metadata stored in the feature registry. This centralization simplifies feature management and reuse.
Develop Feature Pipelines: Create batch or streaming pipelines that transform raw data into feature values, ensuring that the same transformations apply to both offline and online stores to avoid inconsistencies. Efficiently compute features and support on demand feature computation to enable real-time ML workflows and dynamic feature calculations as needed.
Choose Online Store Technology: Select a database optimized for low-latency reads and writes, such as managed Postgres, Redis, or DynamoDB, depending on your scale and latency requirements.
Implement Publishing Mechanisms: Publish feature tables from offline to online stores, supporting streaming updates or scheduled batch refreshes to keep features fresh and consistent, and ensure that new data is continuously ingested and reflected in the online store to keep features up to date.
Set Up Serving APIs: Provide APIs or SDKs for applications to query online features efficiently during model inference, ensuring low-latency and high-throughput access.
Monitor and Maintain: Continuously monitor feature freshness, latency, and data quality to ensure reliable serving and detect anomalies early.
Online Feature Store vs Offline Feature Store
The offline feature store is essential for training machine learning models using comprehensive historical data, enabling point-in-time correctness and backtesting. In contrast, the online feature store is designed for low-latency access to the latest feature values, powering real-time applications like fraud detection, recommendation engines, and personalization systems. Customer data is utilized differently in these stores: historical customer data in the offline feature store supports model training, while real-time customer data in the online feature store enables instant predictions.
The offline feature store is essential for training machine learning models using comprehensive historical data, enabling point-in-time correctness and backtesting. In contrast, the online feature store is designed for low-latency access to the latest feature values, powering real-time applications like fraud detection, recommendation engines, and personalization systems.
Online Feature Store vs. Database
While online feature stores often use databases as their backend, they differ significantly by providing:
Operational Complexity: Managing separate offline and online stores increases maintenance overhead and risk of inconsistencies.
Scalability Challenges: High concurrency and multi-entity joins can strain traditional online stores optimized for simple key-value lookups.
Stale Features: Snapshot-based updates may lead to stale feature data affecting prediction quality.
Limited Query Flexibility: Most online stores are optimized for single-entity lookups and struggle with complex queries involving multiple entities.
These challenges become more pronounced as real-time AI applications grow in complexity and scale.
Choosing an Online Feature Store
When selecting an online feature store, consider the following factors:
Latency and Throughput Requirements: Match capacity to expected query volume and latency service-level agreements (SLAs).
Integration with Existing Pipelines: Ensure compatibility with your data sources and machine learning workflows.
Feature Freshness Needs: Determine whether streaming updates or batch refreshes suffice for your use case.
Scalability and Concurrency: Evaluate support for read replicas and horizontal scaling.
Security and Governance: Look for role-based access control, audit logging, and compliance features.
Monitoring and Alerting: Availability of tools to track feature quality and freshness.
Context Lake as an Architectural Pattern
Beyond traditional online feature stores, unified real-time context layers—often called Context Lakes—are emerging. These systems collapse streaming ingestion, feature serving, and real-time querying into a single platform, providing a unified source of truth for real-time context.
Key benefits include:
Strong consistency across training and serving, eliminating training-serving skew.
Support for multi-entity, iterative, and agentic inference, enabling complex joins and feedback loops.
Simplified operational complexity, reducing the need to manage separate batch and online infrastructures.
Context Lakes represent an architectural evolution addressing the limitations of traditional online feature stores, particularly for advanced AI workloads requiring continuous, multi-dimensional context.
Requirements and Prerequisites
Common requirements for online feature stores include:
Runtime and libraries: For example, Databricks Runtime 16.4 LTS ML or Snowflake snowflake-ml-python ≥1.18.0.
Infrastructure: Network connectivity, TLS-enabled connections, and sufficient capacity.
Authentication: IAM roles, OAuth tokens, service principals, and secrets management.
Schema contracts: Defined primary key columns, compatible data types, event timestamps for time-series features, and non-nullable primary keys.
When publishing feature tables to an online feature store, handling cases where multiple rows share the same primary key value is important to ensure deduplication and maintain data integrity.
Getting Started with Online Feature Stores
To begin using online feature stores, assess your organization's requirements for data freshness, latency, and scalability. Choose from managed feature store platforms, open-source solutions, or custom-built online stores.
Unified real-time data layers allow teams to publish multiple feature tables within one online store, avoiding the complexity of managing multiple infrastructure silos. This reduces training-serving drift by aligning feature computation and serving to the same data model.
Creating and Managing an Online Feature Store
Creating an online store involves:
Selecting capacity tier based on expected queries per second (QPS) and storage needs.
Choosing the deployment region to minimize latency.
Selecting the backing database technology.
Vendor-specific flows include:
Databricks: Use create_online_store via SDK or UI and wait for the published table status to show 'AVAILABLE'.
Snowflake: Create feature store and enable online serving.
Feast: Define feature views, register them, and materialize features.
Managing online stores involves scaling capacity, updating configurations, and monitoring performance. Properly deleting online stores when no longer needed frees resources and avoids downstream issues.
Feature Engineering and Development for Online Stores
Feature engineering transforms raw data from multiple data sources into high-quality features for machine learning models. For online stores, feature engineering must prioritize low latency and high reliability. Feature engineering for online stores focuses on creating and managing machine learning features that are critical for model performance.
Data scientists define, version, and maintain feature definitions to ensure consistency and reusability across teams. Feature stores play a central role in data science workflows by improving data consistency and supporting large-scale ML deployments. Unified real-time data layers often provide SQL-compatible query interfaces, making it easier to inspect and debug features during development and production. They also enforce primary key constraints and ensure data integrity.
Feature Computation
Feature computation is the critical process of transforming raw data into actionable features that power machine learning models. This involves applying a series of data transformations—such as aggregations, filters, and encodings—to generate feature values that capture meaningful patterns and signals from the underlying data.
Feature computation can be executed through batch processing for large-scale historical data or via streaming pipelines for real-time updates, depending on the needs of the application. The feature store provides a standardized framework for defining and orchestrating these feature pipelines, enabling data scientists and engineers to collaborate on creating, updating, and maintaining high-quality features.
By ensuring that feature computation is consistent, reproducible, and aligned with model requirements, feature stores help organizations maximize model performance and maintain data integrity throughout the machine learning lifecycle.
Publishing Features to an Online Store
Publishing involves copying curated feature data from offline tables to the online store, storing only the latest row per entity. This process supports streaming and batch updates.
Prerequisites include valid primary keys, optional event timestamps, and schema compliance.
Platform-specific commands include:
Databricks: publish_table with streaming=True for continuous updates.
Snowflake: Enable online serving on feature views.
Feast: Use materialize or materialize-incremental commands.
After publishing, verify the publishing process completed successfully and that the online published table is in the 'AVAILABLE' state before proceeding with data exploration or integration.
Automate publishing with orchestrated jobs and monitor for failures to avoid stale features.
Keeping Online Features Fresh
Feature freshness is critical for model accuracy. Update options include:
Streaming pipelines for near real-time updates (seconds to minutes).
Scheduled batch jobs for periodic updates.
Streaming offers the lowest latency but at higher cost and complexity, while batch updates are simpler and sufficient for slower-changing features. Many systems combine both approaches.
Set up alerts for lag and failures to maintain freshness. Hybrid architectures support both streaming and batch updates within a single online store instance, providing flexibility and operational simplicity. Monitoring tools enable proactive feature monitoring, helping teams maintain freshness and detect anomalies early.
Querying and Exploring Online Features
Query online stores for debugging and validation using UI tools or SQL editors:
Databricks offers Unity Catalog UI and SQL Editor.
Snowflake supports SQL queries and worksheets.
Querying online stores allows users to efficiently retrieve features for real-time validation and model serving, ensuring that relevant data points are available for tasks like personalization and recommendation.
Endpoints query features in real time for validation and debugging, enabling low-latency retrieval of feature tables for model serving and data validation.
Best practices include avoiding large scans on production online stores and using offline stores for exploratory analysis. Restrict query access appropriately to ensure security and performance.
Systems that handle streaming upserts and low-latency reads in one data layer provide powerful query capabilities with Postgres compatibility, supporting seamless data exploration and debugging.
Using Online Features in Real-Time Applications
Integrate applications with online stores via long-lived clients or APIs. Online feature stores are designed to serve features with low latency, enabling real-time predictions in production systems. Common patterns include:
Fetching features by entity keys.
Combining with real-time context data.
Passing feature vectors to models and returning predictions.
These predictions are typically generated by an online model deployed for real-time inference.
Consider connection pooling, parallel retrieval, caching, graceful timeouts, and latency monitoring to ensure reliable feature serving at scale.
Low-latency APIs and elastic scaling enable real-time applications such as fraud detection, personalization, and dynamic pricing to operate effectively.
Performance, Scaling, and Read Replicas
Achieving low latency under high query volumes involves:
Vertical scaling: Increasing capacity units or instance size.
Horizontal scaling: Sharding by entity ID and adding read replicas.
Connection pooling to improve concurrency.
Read replicas distribute load but may introduce slight lag. Indexing and caching further improve performance.
Test under realistic traffic and monitor resource usage to maintain optimal performance.
Architectures designed for high concurrency and low latency often include built-in support for read replicas and elastic scaling, allowing organizations to handle traffic spikes without manual intervention.
Security, Governance, and Compliance
Protect sensitive data with:
Fine-grained role-based access controls.
Service principals and secret rotation.
Row- and column-level security.
TLS encryption in transit and at rest.
Network restrictions.
Governance features include lineage tracking, audit logs, and feature monitoring.
Minimize data exposure by publishing only necessary features.
Security and governance are integrated into systems that handle streaming upserts and low-latency reads within a unified data layer. Schema evolution is supported securely without downtime.
Deleting Online Tables and Stores Safely
Deleting online tables or stores risks breaking dependencies. Follow a safe process:
1. Inventory all dependencies and consumers.
2. Deprecate features and notify relevant teams.
3. Migrate consumers to alternative data sources or features.
4. Test deletions in lower environments.
5. Schedule maintenance windows for production deletions.
Vendor notes:
Databricks deregisters tables but underlying data may remain; use DROP TABLE to free space.
Deleting stores backing multiple tables affects all associated data.
Ensure published table status confirms removal before proceeding.
Regularly clean up storage and audit unused stores to maintain operational hygiene.
Systems that handle streaming upserts and low-latency reads in one data layer provide tooling and best practices to safely delete online tables and stores, minimizing disruption.
Traditional Online Feature Store vs Unified Context Layer
Feature
Traditional Online Feature Store
Unified Context Layer (Context Lake)
Data update model
Batch and streaming pipelines, managed separately
Unified streaming and batch ingestion in one system
Freshness guarantees
Seconds to minutes, snapshot-based
Continuous, near real-time with strong consistency
Multi-entity joins
Limited, often single-entity lookups
Native support for complex multi-entity joins
Concurrency under load
Scales with read replicas, can bottleneck
Elastic scaling with built-in concurrency management
Agent compatibility
Limited support for iterative feedback loops
Designed for agentic and iterative inference
Operational complexity
High due to dual-store management
Reduced by unified architecture and tooling
Frequently Asked Questions
Conclusion
Online feature stores remain foundational technology for serving feature data with low latency in many real-time machine learning applications, such as fraud detection, recommendation systems, and personalization. They are sufficient when workloads involve straightforward feature lookups, limited multi-entity context, and manageable update rates.
However, as AI systems grow more complex—incorporating agentic behaviors, iterative inference, and requiring continuously fresh, multi-entity context—the limitations of traditional online feature stores become apparent. The operational overhead of maintaining separate offline and online stores, challenges in supporting multi-entity joins, and risks of stale snapshot features necessitate reconsidering architectural approaches.
Teams facing these challenges should evaluate unified real-time context layers, or Context Lakes, which integrate streaming ingestion, feature serving, and querying into a single system. This evolution supports stronger consistency, richer context, and improved scalability, enabling real-time AI applications to deliver more accurate and timely decisions.
Platforms such as Tacnode implement this unified Context Lake architecture and are worth evaluating when workloads require multi-entity joins, continuous updates, and high-concurrency inference under tight latency SLOs.