
Workload Isolation
Learn how to implement effective workload isolation in Tacnode using compute-storage separation architecture for optimal resource management and performance.
Workload isolation in Tacnode leverages the compute-storage separation architecture to logically separate resources and tasks, preventing interference between users, teams, and different types of workloads. This ensures consistent performance and execution accuracy across your data warehouse environment.
Architecture Overview
Compute-Storage Separation
Tacnode’s cloud-native architecture provides:
- Shared Storage: All data stored in a unified, scalable storage layer
- Independent Compute: Isolated compute resources for different workloads
- Flexible Scaling: Independent scaling of compute and storage resources
- Cost Optimization: Pay only for resources you actually use
Core Components
Nodegroups serve as Tacnode’s compute resource abstraction:
- Independent data processing and querying capabilities
- Isolated CPU, memory, and network resources
- Concurrent access to shared databases with serialized consistency
- Elastic scaling based on workload demands
Catalogs provide metadata management:
- Contain all databases accessible to nodegroups
- Atomic unit for instance upgrades
- Prevent metadata version inconsistencies
- Unified governance across related databases
Database Binding controls access patterns:
- Each database bound to one primary nodegroup
- Bound nodegroup handles direct, local read/write operations
- Non-bound nodegroups access via remote operations
- Automatic failover when bound nodegroup becomes unavailable
Common Isolation Scenarios
Development and Production Separation
Isolate development, testing, and production environments to prevent test workloads from impacting critical production operations.
Implementation Strategy:
- Separate nodegroups for each environment
- Dedicated databases per environment
- Resource allocation based on criticality
- Access controls preventing cross-environment interference
Multi-Team Workload Segregation
Provide independent resources for different teams or projects to eliminate resource contention and improve accountability.
Benefits:
- Predictable performance for each team
- Independent scaling and cost management
- Isolated failure domains
- Team-specific optimization strategies
High-Priority Task Protection
Dedicate stable, guaranteed resources to mission-critical workloads that require consistent performance.
Approach:
- Reserved nodegroups for critical applications
- Higher resource allocations
- Priority-based scheduling
- Enhanced monitoring and alerting
Read/Write Workload Separation
Separate analytical and transactional workloads to optimize for different access patterns and performance requirements.
Configuration:
- Dedicated nodegroups for OLTP operations
- Separate analytical nodegroups for OLAP queries
- Optimized resource configurations per workload type
- Independent scaling strategies
Implementation Guide
Planning Your Isolation Strategy
-
Identify Workload Types
- Transactional (OLTP) operations
- Analytical (OLAP) queries
- ETL and data processing jobs
- Interactive and ad-hoc queries
-
Assess Resource Requirements
- CPU and memory needs per workload
- Storage access patterns
- Network bandwidth requirements
- Scaling characteristics
-
Define Isolation Boundaries
- Team or department boundaries
- Environment separation (dev/test/prod)
- Application or service boundaries
- Data sensitivity levels
Nodegroup Architecture Design
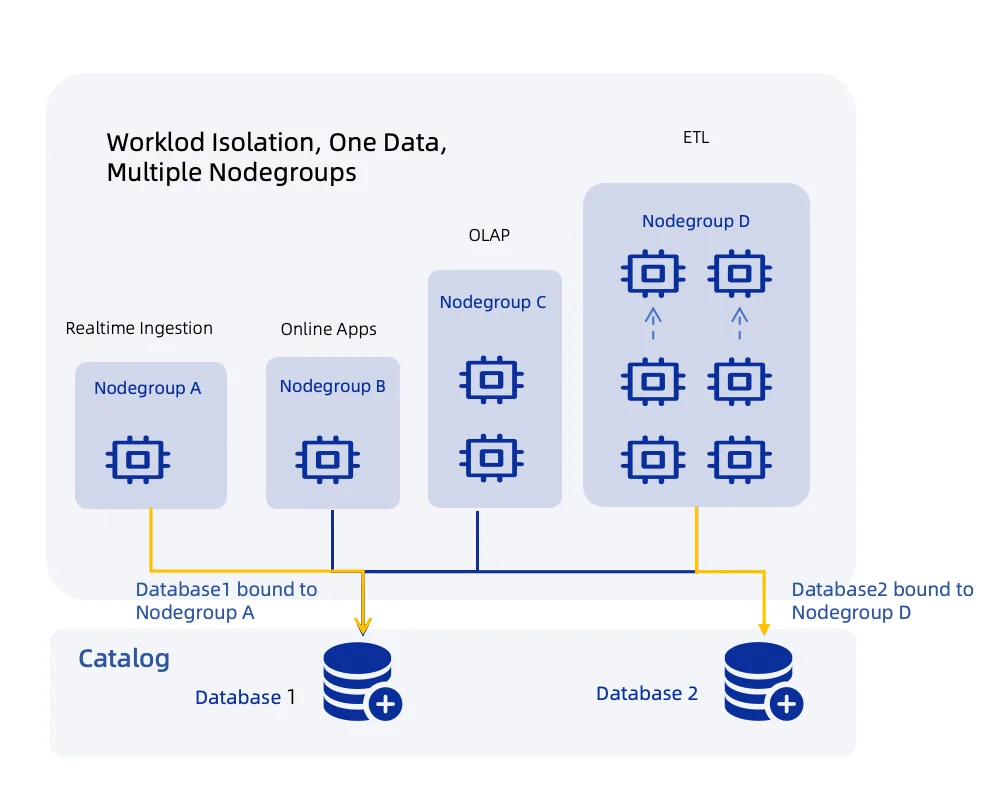
Setting Up Nodegroups
-
Create Nodegroups
- Define compute specifications per workload
- Choose appropriate catalog association
- Configure auto-scaling parameters
- Set resource limits and quotas
-
Configure Database Binding
- Assign primary databases to appropriate nodegroups
- Plan binding strategy for shared databases
- Configure access permissions and security
-
Implement Access Controls
- Set up user authentication and authorization
- Configure network security rules
- Establish audit logging
Database Binding Management
Default Binding Behavior:
- System databases (postgres, template0, template1) auto-bind to creating nodegroup
- User-created databases bind to the nodegroup that creates them
- Binding can be changed through rebinding operations
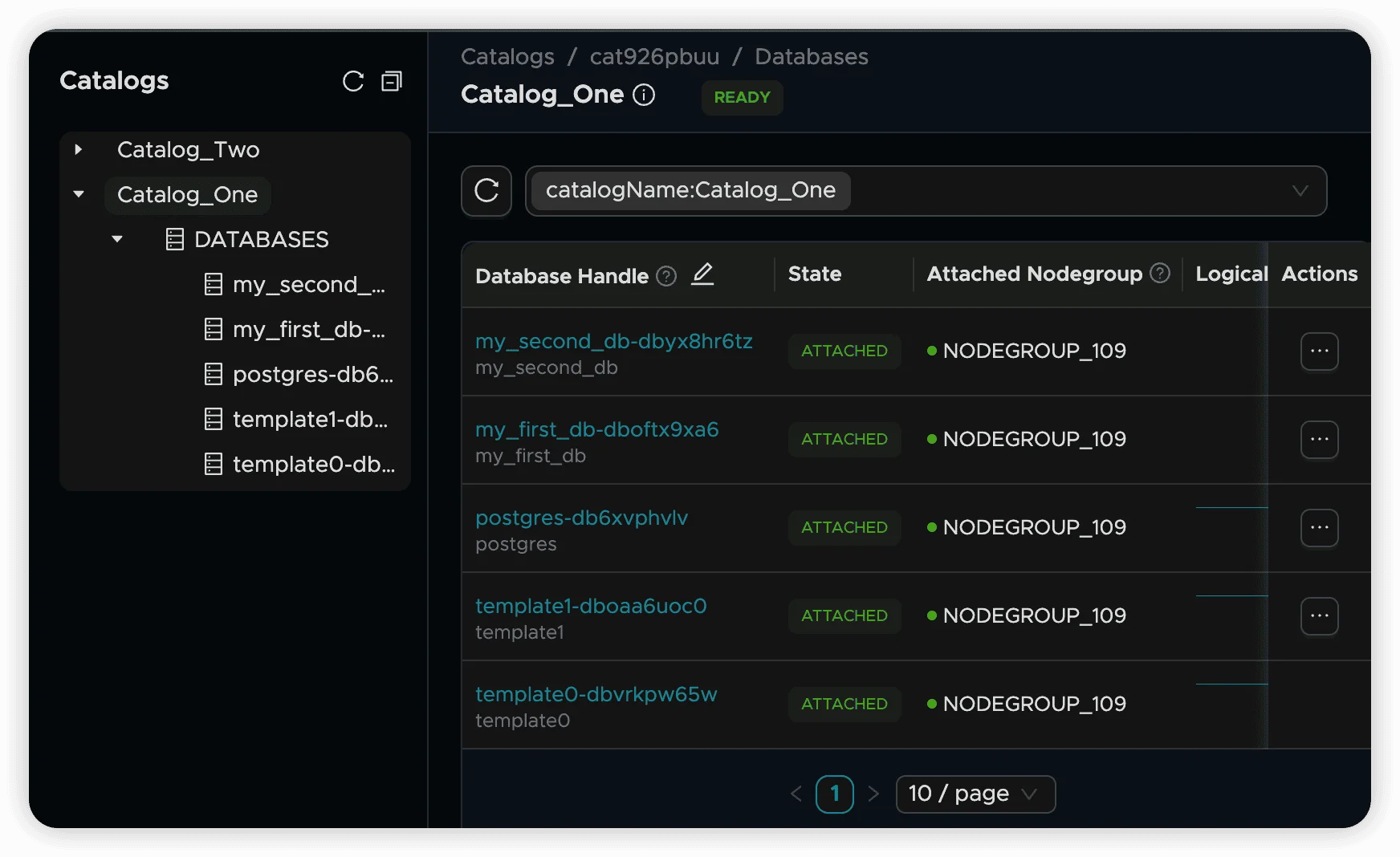
Rebinding Process:
- Unbind from current nodegroup
- Select new target nodegroup
- Specify database name (typically keep original)
- Confirm binding operation
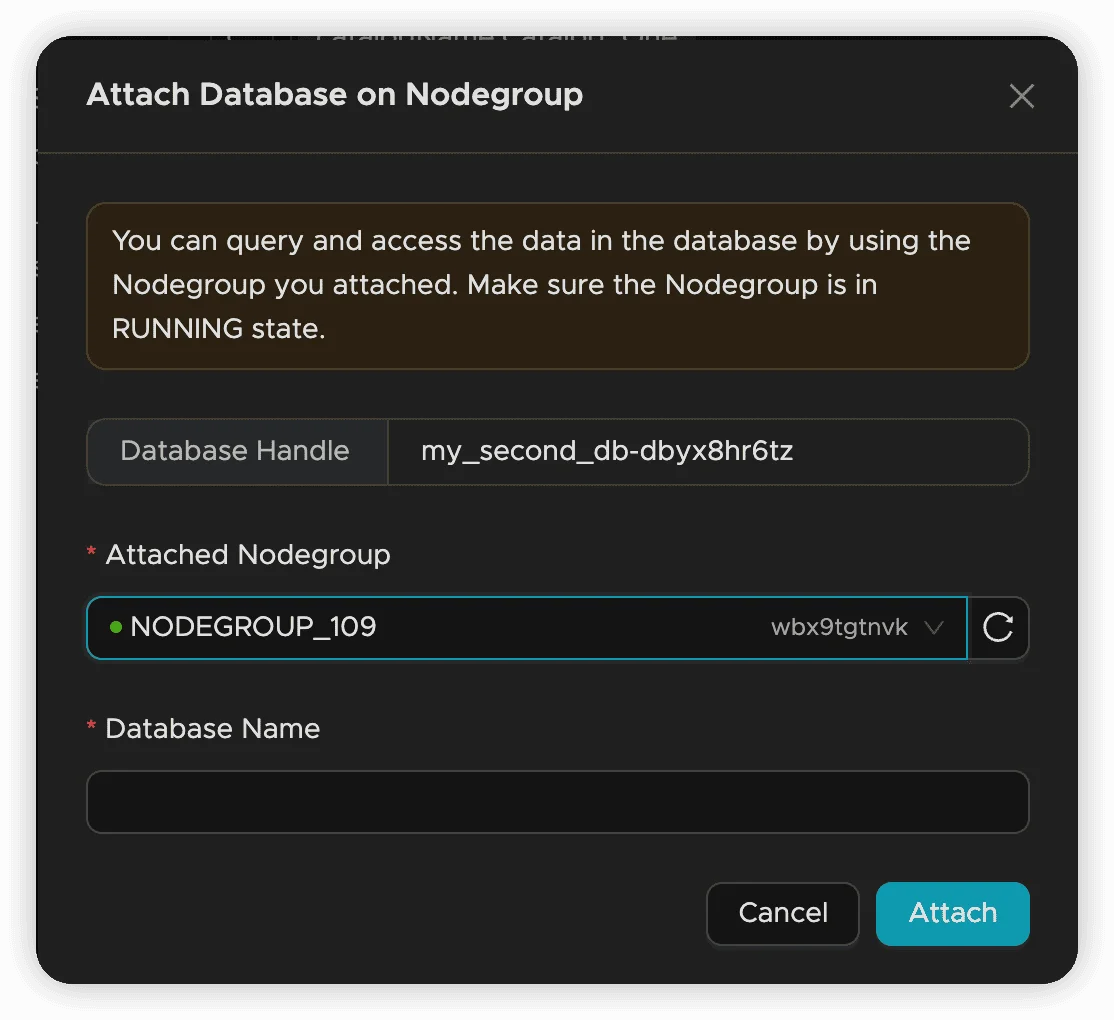
Access Patterns and Performance
Direct Access (Bound Nodegroup):
- Local, high-performance read/write operations
- Optimal for frequent, low-latency queries
- Recommended for primary application workloads
- Best performance for transactional operations
Remote Access (Non-Bound Nodegroups):
- Network-based access to shared databases
- Higher latency but still functional
- Consumes resources on both nodegroups
- Suitable for analytical and reporting workloads
Best Practices
Database Organization
Partition by Responsibility:
- Assign dedicated databases per team or domain
- Align database boundaries with business boundaries
- Implement consistent data within common access scopes
- Use team security officers for database access management
Avoid System Database Usage:
- Never store business data in system databases
- Create dedicated databases for user applications
- Reserve system databases for metadata management only
- Maintain clear separation between system and user data
Authorization Strategy
Global Users:
- Must be explicitly granted access to each database
- Database creators receive automatic access
- Manage permissions centrally across databases
- Implement role-based access controls
Local Users:
- Created per database with
CREATE USER - Database-specific credentials and permissions
- Isolated authentication domains
- Suitable for application-specific access
Nodegroup Optimization
Persistent Workloads:
- Bind write-heavy databases to dedicated nodegroups
- Maintain stable resource allocations
- Optimize for consistent performance
- Implement proper monitoring and alerting
Variable Workloads:
- Use separate ETL nodegroups for batch processing
- Implement dynamic scaling for burst capacity
- Optimize for cost efficiency during idle periods
- Configure appropriate auto-scaling policies
Service Differentiation:
- Production services require higher stability and SLAs
- Internal team usage can prioritize flexibility
- Implement different monitoring and alerting thresholds
- Plan capacity based on service level requirements
Monitoring and Management
Performance Monitoring
- Track resource utilization per nodegroup
- Monitor query performance across workloads
- Identify resource contention and bottlenecks
- Set up proactive alerting for threshold breaches
Cost Management
- Track resource consumption per team or project
- Implement chargeback or showback models
- Optimize resource allocation based on usage patterns
- Plan capacity requirements for different workload types
Operational Excellence
- Document isolation strategies and configurations
- Implement change management processes
- Train teams on proper usage patterns
- Regularly review and optimize isolation boundaries
This comprehensive approach to workload isolation enables enterprise-grade data warehousing with precise operational control and superior resource utilization.